During the 2024-25 academic year, the Northeastern University Archives and Special Collections (NUASC) scanned 24,608 pages of archival materials for both in-person and remote researchers. This output has allowed NUASC to serve more researchers and broaden access to these primary sources by uploading them into the Digital Repository Service (DRS).
A photo from the National Center of Afro-American Artists records
Work to put these reference scans into the DRS began in 2023 with a backlog of scans from NUASC’s remote reference program. Archives staff understood the research value of readily available scans and wanted to make them more accessible to anyone, regardless of institutional affiliation or research goals. Uploading these files into the DRS was a collaborative effort between Metadata and Digital Projects Supervisor Drew Facklam, Reference and Outreach Archivist Molly Brown, and Reference and Reproductions Archivist Grace Millet.
Once a workflow was developed to clean up and provide information about the files, collections were identified based on community and researcher needs, as well as the quantity of scans. As of June 2025, 14,226 pages of digitized materials have been ingested into the DRS. Reference scans have come from the:
Reference scans are completed at a lower resolution than scans used for publication, though they are still entirely legible and usable for research purposes. Another important difference between reference scans and other digitized materials in the DRS is the format of reference scans’ titles, which allow users a glimpse into the inner workings of archival organization.
The titles of these files contain the collection number, box number, folder number, and folder title.
With this knowledge, anyone viewing these files can discern where they are located within NUASC’s collections. This allows for easy reference if a researcher might need to request a higher-quality scan of a specific item.
To learn more about what is available in the Digital Repository Service from NUASC, you can search our digitized collections or reach out to us at archives@northeastern.edu. The public services team is looking forward to continuing this expansion of access to collections stewarded by NUASC!
Gina Nortonsmith, the African American history archivist at Northeastern University. Photo courtesy of Michael Manning.
The Racial Violence Interoperability White Paper Project will serve as a roadmap exploring the possibility of a national project linking various collections of racial violence into a united, interoperable dataset.
Simultaneously a celebration, a launch, and a call to action, Gathering the Red Record highlighted the newest achievements of the BNDA and asked participants for their input and feedback to design future shared goals.
On the first day of the conference, panelists and attendees were introduced to the extensive expansion of the BNDA and the restorative justice milestones the CRRJ have achieved. Since its initial launch in 2022, the BNDA has established itself as one of the most comprehensive digital records of racially motivated homicides collected to date. The archive serves as an open-source repository and database dedicated to identifying, classifying, and providing documentation on anti-Black killings the mid-20th century South. Version 2.0 introduces 290 new victims to the database, along with their corresponding case files, which resulted in over 5,000 new records becoming publicly available. In addition to a massive expansion in records available, Version 2.0 expands the geographic scope of the archive, adding Maryland, Delaware, Washington D.C., Missouri, West Virginia, Indiana, Kentucky, and Oklahoma to the original 11 formerly Confederate states.
Co-founder of the Burnham-Nobles Digital Archive Melissa Nobles and Monica Martinez, project lead for Mapping Violence, speak on The Road to Interoperability White Paper Project. Photo courtesy of Michael Manning.
Day two of the event was dedicated to introducing attendees to The Racial Violence Interoperability White Paper Project and asking for feedback, putting researchers, librarians, and archivists who document historical violence into conversation. Participants were given an early draft, which included instructions on how a national digital project might emerge. Developed in collaboration with eight similar ‘sister’ projects, the paper outlines strategies for aligning data dictionaries, establishing governance, securing funding, and ensuring ethical hosting. Participants then divided into working groups to address project planning and data collection, technology alignment, funding and resources, and federal initiatives on cold case records. The day concluded with conference attendees engaging in guided discussions that explored the feasibility of a national project as described in the White Paper.
As the conference finished, participants were left with possibilities for new collaborations, ideas for funding resources, project design suggestions, and digital publishing possibilities. The fruitful discussions also continue to contribute to the White Paper Project, which is scheduled to be finalized in September.
Captions play a key role in making audio and video content accessible. They benefit not only deaf and hard-of-hearing users, but also second-language learners, researchers scanning interviews, and anyone viewing content in noisy environments.
At the Northeastern University Library, we manage a growing archive of media from lectures and events to oral histories. Manually creating captions for all of this content is not a scalable solution, and outsourcing the task to third party services can be expensive, time-consuming, and inconsistent. Motivated by this, we have been exploring AI-powered speech-to-text tools that could generate high-quality captions more efficiently and cost-effectively.
Figure 1: Example of an ideal transcription output
We started by testing Autosub, an open-source tool for generating subtitles. Even using a maintained fork (copies of the original project that add features, fix bugs, or adapt the code for different use cases), Autosub did not offer significant time savings, and it was eventually dropped.
In summer 2023, the team began using OpenAI’s Whisper, which immediately cut captioning time in half. However, it lacked key features like speaker diarization (the process of segmenting a speech signal based on the identity of the speakers), and it often stumbled on long stretches of music or background noise which would require extra cleanup and made the output harder to use at scale.
As the AI for Digital Collections co-op on the Digital Production Services (DPS) team, I was responsible for researching and testing Whisper forks that could be realistically adopted by our team. I tested model performance, wrote scripts to automate captioning, debugged issues, and prepared tools for long-term use within our infrastructure.
Phase 1: Evaluating Whisper Forks
We looked for a model that could:
Handle speaker diarization
Distinguish between speech and non-speech (music, applause, etc.)
Output standard subtitle formats (like VTT/SRT)
Be scriptable and actively maintained
We tested several forks, including WhisperX, Faster Whisper, Insanely Fast Whisper, and more. Many were either too fragile, missing key features, or poorly maintained. WhisperX stood out as the most well-rounded: it offered word-level timestamps, basic diarization, reasonable speed, and ongoing development support.
Phase 2: Performance Testing
Once we chose WhisperX, we compared its various models to OpenAI’s original Whisper models, including large-v1, v2, v3, large-v3-turbo, and turbo. We tested six videos, each with different lengths and levels of background noises, and compared the models based on Word Error Rate (WER) (how often the transcription differed from a “gold standard, or human-created or -edited transcript), and processing time (how long it took each model to generate captions).
WhisperX’s large-v3 model consistently performed well, balancing speed and accuracy even on noisy or complex audio. OpenAI’s turbo and large-v3-turbo delivered strong performance but lacked diarization features.
Phase 3: Timestamp Accuracy Evaluation
Next, we assessed how precisely each model aligned subtitles to the actual audio — crucial for usability. We compared outputs from the WhisperX large-v3 model and the OpenAI turbo and large-v3-turbo models.
We used a gold standard transcript with human-reviewed subtitles as our benchmark. For each model’s output, we measured:
Start Mean Absolute Error (MAE) — average timing difference between predicted and actual subtitle start times
End MAE — same as Start MAE, but for subtitle end times
Start % < o.5s — percentage of subtitles with start times less than 0.5 seconds off
End % < 0.5s — same for start % < 0.5s, for end times
Alignment rate — overall percentage of words correctly aligned in time
WhisperX’s large-v3 model outperformed all other models significantly. In most of our test videos, it showed:
Much lower MAE scores for both start and end timestamps
Higher percentages of accurately timed subtitles (within the 0.5-second range)
Better overall word alignment rates
In fact, in several test cases, WhisperX was nearly three times more accurate than the best-performing OpenAI Whisper models in terms of timing precision.
Figure 2: WhisperX output vs. gold-standard transcript in a high-WER case
In one particular case, one WER result for WhisperX large-v3 showed a surprisingly disappointing score of 94% errors. When I checked the difference log to investigate, it was that the model had transcribed background speech that was not present in the gold standard transcript. So, while it was technically penalized, WhisperX was actually picking up audio that the gold standard did not include. This highlighted both the model’s sensitivity and the limitations of relying solely on WER for evaluating accuracy.
Figure 2 shows exactly that. On the left, WhisperX (denoted “HYP”) transcribed everything it heard, while the gold standard transcript (denoted “REF”) cut off early and labeled the rest as background noise (shown on the right).
What’s Next: Integrating WhisperX
We have now deployed WhisperX’s large-v3 model to the library’s internal server. It’s actively being used to generate captions for incoming audio and video materials. This allows:
A significant reduction in manual labor for our DPS team
The potential for faster turnaround on caption requests
A scalable solution for future projects involving large media archives
Conclusion
As libraries continue to manage growing volumes of audio and video content, scalable and accurate captioning has become essential, not only for accessibility, but also for discoverability and long-term usability. Through this project, we identified WhisperX as a practical open-source solution that significantly improves transcription speed, speaker diarization, and timestamp precision. While no tool is perfect, WhisperX offers a strong foundation for building more efficient and inclusive media workflows in the library setting.
Reflections and Acknowledgements
This project helped me understand just how much thought and precision goes into building effective captioning systems. Tools like WhisperX offer powerful capabilities, but they still require careful evaluation, thoughtful tuning, and human oversight. I am incredibly grateful to have contributed to a project that could drastically reduce the time and effort required to caption large volumes of media, this way enabling broader access and creating long-term impact across the library’s AV collections.
Finally, I would like to thank the Digital Productions Services team for the opportunity and their guidance and support throughout this project — especially Sarah Sweeney, Kimberly Kennedy, Drew Facklam, and Rob Chavez, whose insights and feedback were invaluable.
The Digital Repository Service (DRS) is an institutional repository that was designed by the Northeastern University Library to help members of the Northeastern community organize, store, and share the digital materials that are important to their role or responsibilities at the university. This can include scholarly works created by faculty and students; supporting materials used in research; photographs and documents that represent the history of the community; or materials that support the day-to-day operations of the university.
While the DRS itself is a technical system that stores digital files and associated information to help users find what they need, we also consider the DRS to be a service for the university community: library staff are here to help you organize, store, share, and manage the digital materials that have long-lasting value for the university community and beyond.
Published research from the Northeastern community available in the DRS.
Northeastern is not alone in this endeavor. Repository services are now standard practice for most academic institutions, including Harvard University Library (who also use the name “Digital Repository Service”), Stanford University Library (a leader in technical development for repository systems), Tufts Libraries, and other institutions around the world.
Who uses the DRS?
The DRS has been used by faculty, staff, students, and researchers from all corners of the university community for 10 years. There are too many use cases to mention in one brief blog post, but here are some trends we’ve seen in what users choose to deposit the last few years.
Publications and data that supports published research
Event recordings, photographs, newspapers, and almost any kind of material you can think of to support the day-to-day operations and activity at the university
Student research projects and classwork, like oral histories and research projects. Students are also required to contribute their final version of their thesis or dissertation.
Digitized and born-digital records from the Archives and Special Collections, including photographs, documents, and audio and video recordings
These files, and all the other audio, video, document, and photograph files in the DRS, have been viewed or downloaded 11.2 million times since the DRS first launched in 2015. Nearly half of the files in the DRS are made available to the public and are therefore available for the wider world to discover. Materials in the DRS have been cited in reporting by CNN, Pitchfork, WBUR, and Atlas Obscura, among others, and are regularly shared on social media or in Reddit threads. As a result, Northeastern continues to contribute the work produced here to the larger scholarly and cultural record, and to the larger world.
Who supports the DRS?
The day-to-day work managing, maintaining, and supporting users of the service comes from staff in Digital Production Services:
Kim Kennedy supervises the digitization of physical materials and processing of born-digital and digitized materials.
Drew Facklam and Emily Allen create and maintain the descriptive metadata that helps you find what you need.
And all of us in the department, including part-time staff, are responsible for general management of the system, including batch ingesting materials, holding consultations and training sessions, answering questions, and leading conversations about how to improve the system and the service.
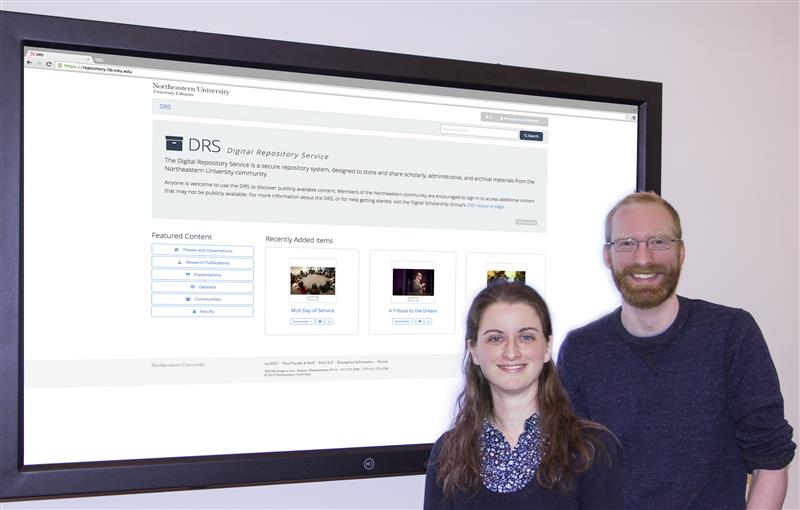
Sarah Sweeney and David Cliff, DRS staff, posing in 2015 with the homepage of the recently launched DRS.
The DRS is also supported by a number of library staff members across the library:
David Cliff, Senior Digital Library Developer in Digital Infrastructures, is the DRS’ lead developer and system administrator.
Ernesto Valencia and Rob Chavez from the Library Technology Services and Infrastructure departments also provide development support and system administration.
Many librarians in the Research and Instruction department do outreach about the service and support faculty as they figure out how to use it in their work.
Jen Ferguson from Research Data Services also connects faculty and researchers to the DRS, while also providing data management support for those wishing to use the DRS to store their data.
Members of the library administration, including Dan Cohen, Evan Simpson, Tracey Harik, and the recently retired Patrick Yott have contributed their unwavering support and advocacy for developing and maintaining system an service.
We are all here to help you figure out how the DRS may be used to make your work and academic life easier. To dive deeper into what the DRS is and how to use it, visit the DRS subject guide or contact me or my team.
BOSTON, MA. – Master student Zarina Dawlat, studies for an accounting exam in Snell Library on Aug. 19, 2024. Photo by Matthew Modoono/Northeastern University
Are you excited for classes to begin this fall? Can’t wait to get started? We’ve got you covered! Beat the heat this summer inside at your computer. Set yourself up for fall academic success with information on: