Northeastern University Library’s procedure for digitizing physical materials utilizes a few different workflows for processing print documents, photographs, and analog audio and video recordings. Each step in the digitization workflow, from collection review to scanning to metadata description, is performed with thorough attention to detail, and it can take years to completely process a collection. For example, the approximately 1.6 million photographs in The Boston Globe Library collection held by the Northeastern University Archives and Special Collections may take several decades to complete!
What if some of these steps could be improved by using artificial intelligence technologies to complete portions of the work, freeing staff to focus more effort on the workflow elements that require human attention? Read on for a very brief overview of artificial intelligence and three potential options for processing The Boston Globe Library collection and other digital collections held by the Library.
What is artificial intelligence and machine learning?
Artificial intelligence (AI) is a broad term used for many different technologies that attempt to emulate human reasoning in some way. Machine learning (ML) is a subset of AI where a program is taught how to learn and reason on its own. The program learns by using an algorithm to process existing data and find patterns. Every pattern prediction is evaluated and scored according to how accurate the prediction may or may not be until the predictions reach an acceptable level of accuracy.
ML may be supervised or unsupervised, depending on the type of result needed. Supervised learning is when instructions are provided to assist the algorithm to learn how to identify patterns expected to the researcher. Unsupervised learning is when the algorithm is fed data and discovers its own patterns that may be unknown to the researcher.
Ethics
As we undertake this work, it is important to be aware that AI technologies are human-made and therefore human biases are embedded directly within the technology itself. Because AI technologies can be employed at such a large scale, the potential for negative impact caused by these biases is greater than with tools that require standard human effort. Although it is tempting to adopt and employ a useful technology as quickly as possible, this is an area of research where it is imperative that we make sure the work aligns with our institutional ethics and privacy practices before it is implemented.
What AI or ML techniques could be used to help process digital collections?
OCR: The most widely known and used form of AI in digital collections practices may be recognition of printed text using Optical Character Recognition, or OCR. OCR is the process of analyzing printed text and extracting the text objects, like letters, words, sentences. The results may be embedded directly in the file, like a PDF with OCR’d text, or stored separately, like in a METS-ALTO file, or both.

OCR works rather well for modern text documents, especially those in English, but a particular challenge for OCR is historical documents. For more about this challenge, I recommend A Research Agenda for Historical and Multilingual OCR, a fairly recent report published by NULab.
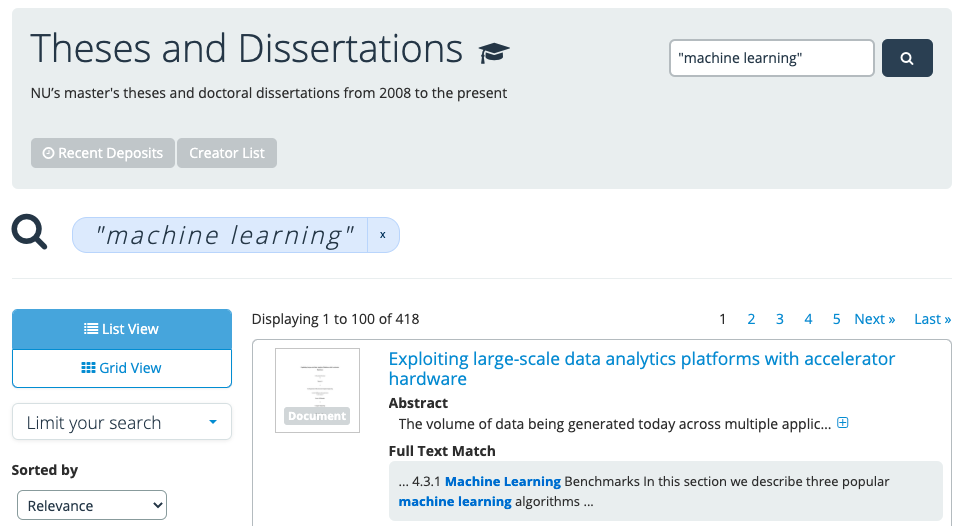
We can already see the benefit of using OCR in the library’s Digital Repository Service, as files with OCR text embedded in the file have the full text extracted and stored alongside the text file. That text is indexed and improves discoverability of text files by retrieving files that match search terms in the file’s metadata or the full text.

HTR: Handwritten Text Recognition, or HTR, is like OCR, but for handwritten, not typewritten, text. Handwriting is very unique to an individual and poses a difficult challenge for teaching machines to interpret it. HTR relies heavily on having lots of data to train a model (in this case, lots of digitized images of handwriting), so even once a model is accurately trained on one set of handwriting, it may not be useful for accurately interpreting another set. Transkribus is a project attempting to navigate this challenge by creating training sets for batches of handwriting data. Researchers submit at least 100 transcribed images for a particular handwriting set to Transkribus and Transkribus uses that set as training data to create an HTR model to process the remaining corpus of handwritten text. HTR is appealing for the Boston Globe collection, as the backs of the photographs contain handwritten text describing the image, including the photographer name, date the photograph was taken, classification information, and perhaps a description or an address.
Computer Vision: Computer vision refers to AI technologies that allow machines to work with images and video, essentially training a machine to “see”. This type of AI is particularly challenging because it requires the machine to learn how to observe and analyze a picture and understand the content. Algorithms for computer vision are trained to identify patterns of different objects or people and attempt to accurately sort and identify the patterns. In a picture of the Northeastern campus, for example, a computer vision algorithm may be able to identify building objects or people objects or tree objects.
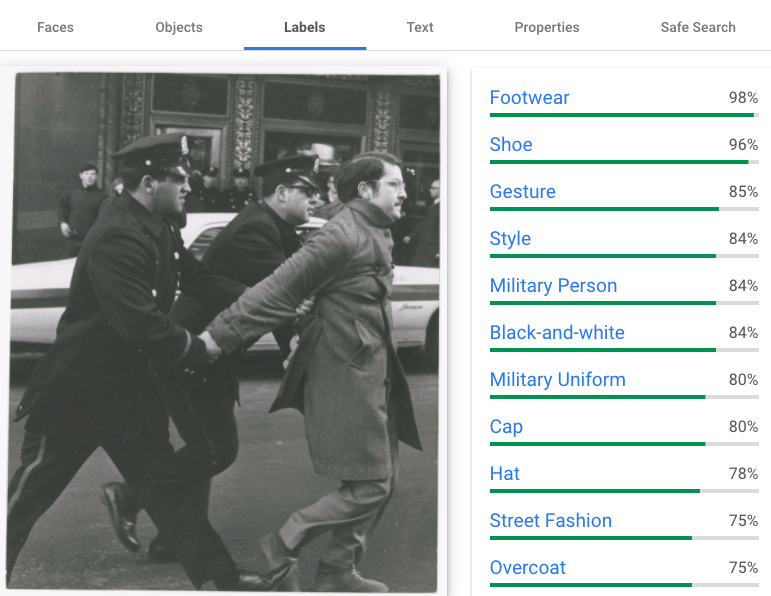
When used in digital collections workflows, the output produced by computer vision tools will need to be evaluated for its usefulness and accuracy. In the above example, the terms returned to describe the image are technically present in the photo (the subjects are wearing shoes and hats and overcoats), but the terms do not adequately capture the spirit of the image (a person being detained at a demonstration).
There are a lot of ethical concerns about using computer vision, especially for recognizing faces and assigning emotions. If we were to employ this particular technology, it may be able to generate keywords or other descriptive metadata for the Boston Globe collection that may not be present on the back of an image, but we would need to be careful to make sure that the process does not embed problematic assessments into the description, like describing an image of a protest as a riot.
Computer vision is already being employed in some digital collection workflows. Carnegie Mellon University Libraries has developed an internal tool called CAMPI to help archivists enhance metadata. An archivist uses the software to tag selected images, then the program returns other images it identifies as visually similar, regardless of its box and folder, allowing the archivist to easily apply the same tags to those visually similar images without having to manually seek them out.
Many other aspects of AI and ML technologies will need to be researched and evaluated before they can be integrated into our digital collections workflows. We will need to evaluate tools and identify the skills that are needed to train staff to perform the work. We will also continue to watch leaders in this space as they dive deep into the world of artificial intelligence for library work.
Recommended resources:
Machine Learning + Libraries: A Report on the State of the Field / Ryan Cordell : https://blogs.loc.gov/thesignal/2020/07/machine-learning-libraries-a-report-on-the-state-of-the-field/
Digital Libraries, Intelligent Data Analytics, and Augmented Description / University Of Nebraska–Lincoln: https://digitalcommons.unl.edu/libraryscience/396/