Since 1977, Northeastern University has hosted events dedicated to remembering and learning the lessons of the Holocaust. Since 1991, the Holocaust and Genocide Awareness Committee (HGAC) has organized these programs, with this year’s events running the week of March 16.
The records of the HGAC live in the Archives and Special Collections, and the Digital Production Services staff have been creating captions for videos available in the Digital Repository Service. We’re currently focusing on videos of Holocaust lectures and survivors.
Captioning survivor testimonies has been an emotional experience as I’ve heard people’s stories of trauma, often repeatedly as the same survivors have spoken at Northeastern multiple times. However, their stories also offer hope and advice for how to make a difference, no matter the circumstances.
“Because of Oskar and Emilie Schindler, I was given a chance to grow up, to get married, to have children and to have grandchildren. And because I am an eyewitness to some of the most horrific crimes committee against innocent people, I’m also an eyewitness to what morality and humanity and goodness can do, because Oskar Schindler had proven to the world that they did not have to stand by and do nothing, that there is always something that could have been done. Oskar Schindler and Emilie Schindler could not stand by, avert their eyes to the slaughter of innocent people. They acted on their faith, on their beliefs, [regarding] their safety, because they felt that was the only thing they could do, because to be a bystander is a bigger sin than to be a perpetrator.” (2002)
Rena Finder speaking in 2010.
She discusses the moral impact of small acts from ordinary people:
“And this is a moral for everyone, that each and every one of you has the power to make a difference, because each and every one of you can make a decision. Not to stand by when you see injustice done, but to make changes. You have to participate…There is always something you can do. You don’t have to stand by when you see someone beating up on somebody else. You don’t have to listen when somebody makes an ethnic joke. You have the power to walk away. You have the power to say, ‘I don’t want to hear it. You can’t say that in front of me.’ You have the power to extend a hand to your friend, to your neighbor, regardless of their race or religion.” (2002)
Raymond Fridmann speaking in 1994.
Survivor Raymond Fridmann focuses on how to have a larger influence on the world:
“If there’s one thing you should do and I say that every year here, register to vote because this is the only expression you have to make sure that you got the government of the people you choose. Do not take it for granted that your vote does not count. Your vote counts. Get educated. Get educated, for you to have jobs. Get educated and read history because if we don’t read history, we will go back into the same holes.” (2002)
Finder ends with a call to action:
“It’s really up to you. You have the power to write to the president, to the congress, to the senator. Don’t ever believe that a small group of committed citizens can’t change things, because those are the only ones that can. And you are going to become just that group that will change.” (2002)
I’m excited to make these materials more accessible, and hope these moving testimonies continue to inspire their listeners to take action.
The Digital Repository Service (DRS) is a dynamic place that showcases the variety of projects and scholarly work completed by members of the Northeastern community. Every year, new material is added to the DRS, including theses and dissertations, datasets, presentations, photographs, archival collections, and more. To conclude our series of blog posts celebrating 10 years of the DRS, I thought it would be fun to look back at this past year.
First, some statistics! In 2025…
75,851 new files were added to the DRS. There are 516,254 files total.
1,567 new users signed onto the DRS.
1,557,614 interactions (views, downloads, and streams) occurred.
Next, I wanted to put a spotlight on some work completed this past year. This blog post focuses on projects related to Digital Production Services (DPS), the department I’m a part of.1 DPS is responsible for the day-to-day management and upkeep of the DRS.2 Our work this year involved collaborating with different groups, departments, and people across the university, adding new collections and files to the DRS and completing metadata updates to existing collections, among other things.
Collaboration across the university…
Mills College Art Museum (MCAM): Collection images and exhibition catalogs from the museum were added to the DRS. MCAM, located in Oakland, was founded in 1925 and its collections include over 12,000 objects. Highlights include Californian and Asian ceramics and important works by prominent women artists. To learn more about the museum, visit their website.
Civil Rights and Restorative Justice Project (CRRJ): Cataloging work continued this year, and new items were added. This project showcases collaboration between many different people at Northeastern, including the School of Law, Archives and Special Collections, the Digital Scholarship Group, and DPS. To learn more about the work of the CRRJ, visit their website. Read more about this work in blog posts written by Archives Assistants Stephanie Bennett Rahmat and Annie Ross.
Electronic Theses and Dissertations (ETDs): Every year, new theses and dissertations showcasing the breadth and depth of scholarship at Northeastern are added to the DRS. In 2025, 577 were added. To break this down by college:
Work related to the Northeastern University Archives and Special Collections…
An example of a tear sheet from the Larry Katz Collection: a newspaper article written by Katz from the Boston Herald about Mariah Carey. https://hdl.handle.net/2047/D20775370
Urban Confrontation (Office of Education Resources at the Communications Center) and Issue and Inquiry (Division of Instructional Communications): Two radio programs were added to the DRS. Both programs originally aired on Northeastern’s WRBB and highlight public affairs issues and other challenges facing Americans in 1970-71. To read more about this work, check out this blog post by Chelsea McNeil, a former metadata assistant.
Larry Katz Tear Sheets: Tear sheets (documents that provide proof of publication) were added to the Larry Katz Collection. In this case, the Katz tear sheets are the newspaper articles or clippings Katz wrote for The Real Paper and the Boston Herald. Katz’ interviews were previously added to the DRS. With the addition of the tear sheets, new connections can be made between the interviews and articles.
Freedom House: New items were added to the Desegregation and Education sub-series of the collection. If you’re interested in learning more about community activism, busing, and desegregation in Boston Public Schools and efforts to provide all children with equal access to educational opportunities, this sub-series is a great starting place.
Boston Gay Men’s Chorus (BGMC): New audio and video recordings (mainly of performances) by the BGMC were added. A portion of the college is holiday concerts, and though we’re past the holiday season, I can’t help but recommend listening to some holiday music (or put this on your to-do list for later this year!). Here’s a link to “Home for the Holidays,” the 2001 holiday concert. To learn more about the BGMC, visit their website.
The Cauldron: New editions of Northeastern’s yearbook were added. The Cauldron was first published in 1917 and is also available to browse through the Internet Archive.
Reference scans: Archives and Special Collections (NUASC) scanned over 46,000 pages of material for researchers this past year. These scans are now being incrementally added to collections with minimal metadata to make NUASC’s records more accessible. To learn more about this work, read Grace Millet’s blog post. So far, 8,584 pages have been added to NUASC’s DRS collections for:
I wanted to wrap up this post by previewing the collections, projects, and collaborations for the DRS in 2026.
Work has started on the digitization and description of collections related to Elma Lewis, founder of the Elma Lewis School of Fine Arts (1950), the National Center of Afro-American Artists (1968), and the Museum of the National Center of Afro-American Artists (1969). Through these institutions, she shaped and influenced Black art, artists, and performers in Boston and beyond. This work is made possible by a Community Preservation Art grant from the City of Boston. To learn more about this work, read the blog post written by Giordana Mecagni, Head of NUASC, and Molly Brown, Reference and Outreach Librarian.
Metadata updates are currently in progress for the WFNX Collection, which mainly consists of clips and episodes from The Sandbox, a beloved morning radio program that aired on WFNX, a radio station broadcasting in the Greater Boston area from 1982-2012. These updates are expected to be completed early this year.
Planning has begun for DRS v2. There are many improvements planned for behind the scenes and changes that will impact how users interact with the DRS. We’re excited to get the ball rolling and sharing more about this work in the future.
It’s an amazing accomplishment to reach 10 years, and a testament to the passion and dedication of the Northeastern community. We look forward to the next 10 years, which will bring new challenges, collections, opportunities, and collaborations.3
If you’re interested in depositing your materials to the DRS, or working or collaborating with DPS, please email library-DPS@northeastern.edu — we’d love to hear from you! To read more about DPS services, visit our departmental directory.
Footnotes:
There are so many different communities, groups, and people that work on and contribute to the DRS. This blog post is only able to capture a snapshot of all that goes on.↩︎
Many library staff members work alongside DPS to support the DRS. To learn more about the people behind the DRS and the DRS itself, read What is the DRS and who is it for? by Sarah Sweeney, Head of Digital Production Services.↩︎
A big thank you to my colleagues in DPS (Sarah Sweeney, Drew Facklam, and Kim Kennedy) and NUASC (Molly Brown) for their help and feedback, which contributed greatly to this post.↩︎
This etching on paper by Italian draughtsman and printmaker Stefano della Bella is likely to have been one of the works that brought the DRS to its 500,000th upload.
This milestone comes as the library celebrates a decade of supporting the DRS as a service for the university community. In those 10 years, a few files have emerged as the most popular, seeing consistent traffic year after year, including:
This “Ancient Aliens” meme from the One Marathon collection is the most viewed file in the DRS.
Internet Meme: “Ancient Aliens” meme — The most viewed file in the DRS is a variation of the Ancient Aliens meme from the Our Marathon collection, which contains crowdsourced images, documents, and audio-visual content related to the 2013 bombing of the Boston Marathon. The file has been viewed 51,598 times since 2018, averaging more than 7,000 views a year.
Profile of Nonverbal Sensitivity (PONS): Full Test — The most streamed audio or video file in the DRS is a test instrument that is widely used in the field of psychology. The full test video has been streamed 21,979 since 2015, averaging more than 2,000 streams a year.
Northeastern’s electronic theses and dissertations (ETDs) provide a valuable record of the university’s scholarly contributions, capturing the evolution of research across numerous academic disciplines over the past two decades. The Digital Repository Service (DRS) preserves all ETDs from 2008 onward, along with selected earlier works, creating a collection of more than 7,500 items spanning over 30 departments and nearly 70 academic programs.
As some of the DRS’ most frequently accessed materials, ETDs offer rich insights into the university’s academic history and digital presence. To celebrate the 10th anniversary of the DRS, Digital Production Services (DPS) — the department responsible for managing both the DRS and ETDs — set out to share insights into how theses and dissertations are added to the repository and how Northeastern’s ETD collections have evolved over time.
ETD Creation to DRS Ingest: Process Overview
The ETDs are initially submitted to ProQuest by graduate students as a condition of their graduation. The rules for the submission package and document organization are determined by each program. Once the submission is completed and the student fills out information about their ETD, the file and metadata are sent in via a zip file to a library server. Over the last 5+ years, a local workflow has been developed to:
Export the files and move backups to other networked drives
Record submissions in a spreadsheet to ensure file provenance
Document any additional information, such as embargo dates or original file names, in case there are issues with the submission
Review, normalize, and transform the existing ProQuest metadata to create DRS-compliant records for each file
Add degree, school, and department information to each record to support the DRS collection structure
Ingest the ETDs into their corresponding collections in the DRS
Generate digital object identifiers (DOIs) for each ETD
Conduct name authority control on all advisor and committee member names
Filtering options for ETDs in the DRS.
New ETDs are processed and ingested every 2-3 months, depending on the time of year and the volume of ETD submissions, and can involve anywhere from 30 to 100 ETDs at a time. DOIs are generated and ETD contributor names are reviewed bi-annually.
General Growth
The total number of ETDs submitted by Northeastern students has increased significantly since 2008. From 2008-2010, there was an average of around 190 documents submitted annually. As the 2010s continued, that number steadily increased from 353 in 2013 to 583 in 2019. There was a small dip in 2020, possibly due to COVID interrupting degree completions, but since then, there have been approximately 540-590 ETDs submitted each year.
Degree Distribution
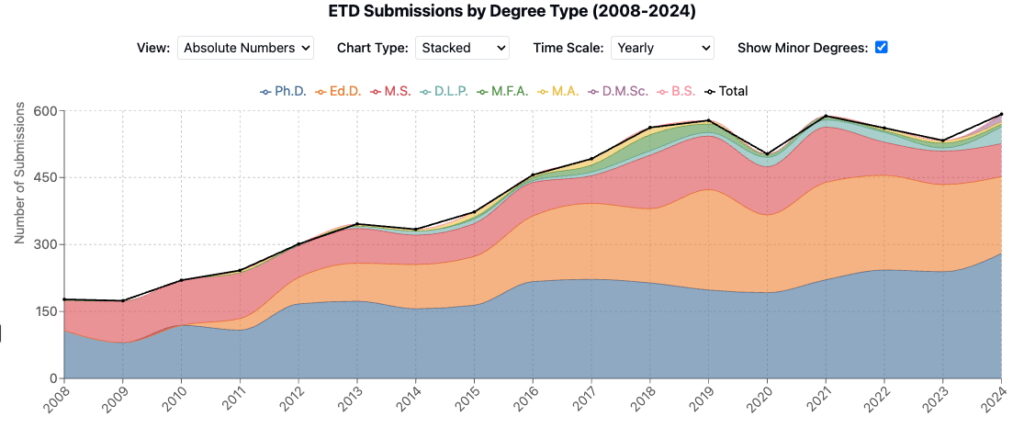
Almost 90% of ETDs produced from 2008-2010 were either for Ph.D. or MS degrees, but as the School of Education started producing theses for the Ed.D. degree, those quickly became common, and represented 34% of all ETDs produced by 2020. Additional degree programs also started producing ETDs from 2010-2020, with MA, DLP, and MFA degrees representing almost 5% of ETDs during that period. In the last 4-5 years, numbers have stabilized, with Ph.D. dissertations regularly accounting for around 45% of all ETDs, Ed.D. theses around 35%, MS theses hovering around 15%, and all other degree types filling out the remaining 5%.
Data visualization showing ETD submissions by degree type from 2008-2014. Created by Claude (Antropic) based on analysis of dataset exported from the DRS and transformed by the author. Generated May 2025.
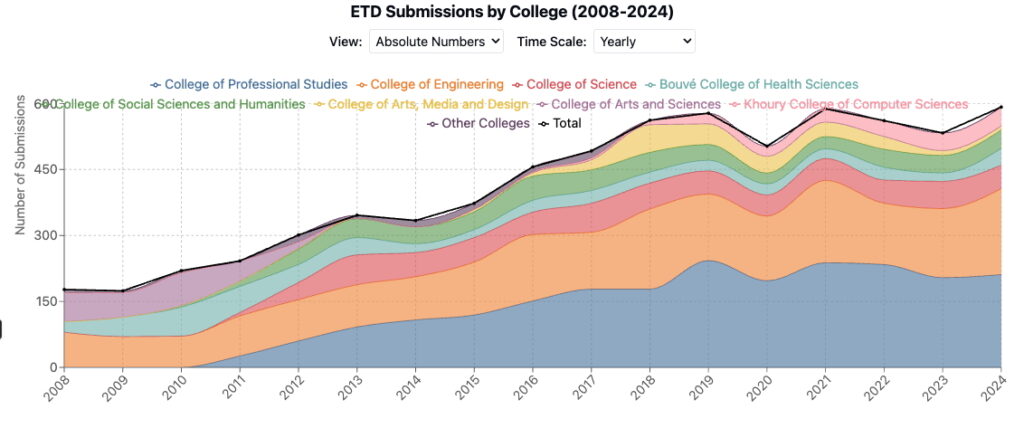
College, School, Department, and Program Representation
Data visualization showing ETD submission by college from 2008-2024. Created by Claude (Anthropic) based on analysis exported from the DRS and transformed by the author. Generated May 2025.
Department of Electrical and Computer Engineering (910)
Department of Mechanical and Industrial Engineering (705)
Department of Chemistry and Chemical Biology (316)
Department of Art + Design (271)
Computer Science Program (245)
Department of Civil and Environmental Engineering (242)
School of Pharmacy (212)
Department of Chemical Engineering (209)
Department of Counseling and Applied Educational Psychology (202)
Addition of Supplementary Files
The first ETD to include supplemental files, or files submitted to accompany the ETD PDF file, first appeared in 2013. The number of supplemental files grew throughout the 2010s, with supplemental material representing 4% of all ETD file submissions during that time. Since 2020, the number of supplemental files has seen a slight decline, but there are still regular submissions, with 26 provided in 2024. The college that most often submits these files is the College of Arts, Media, and Design (CAMD), with almost 1 in 4 theses including supplemental materials.
Other notable contributors include COE and the College of Social Sciences and Humanities (CSSH). The smallest contributor is CPS, which, despite being the largest contributor of ETDs overall, has only 11 total supplemental files since 2013.
Screenshot of a supplementary file page that features a photograph stored in the DRS. Original photo by Hannah M. Groudas.
New Undergraduate Theses
More recently, undergraduate programs from departments like Biology, Biochemistry, Marine and Environmental Science, and Psychology have begun to submit electronic theses directly to DPS staff. DPS offers the same level of service to the undergraduate theses as the graduate ETDs and includes the same metadata in each accompanying description to ensure these materials are as discoverable as the graduate theses and dissertations.
Maintaining ETDs is a vital part of the DRS’ mission, presenting unique challenges that library staff are well-equipped to manage. As the submission processes, file formats, academic disciplines, and research topics continue to evolve, the library remains committed to preserving and providing access to these scholarly works. Through ongoing innovation and stewardship, we ensure that the academic contributions and history of Northeastern students are securely archived and shared for generations to come.
AI acknowledgement: Claude Projects was used to generate data visualizations based on ETD metadata exported from the DRS and transformed into a spreadsheet dataset. Specific visualizations based on identified columns were requested. Project instructions, prompts, and dataset are available here.
In our series of posts highlighting 10 years of the Digital Repository Service (DRS), I wanted to shine a light on the audio and video materials we host that engage with global warming, pollution, and the climate emergency.
Student Research
The annual Research, Innovation, and Scholarship Expo (RISE) is an opportunity for students and faculty to showcase their research focused on solutions to real-life problems. In 2021, these presentations were recorded.
The debt calculator: a gratitude-based approach to environmental justice by Kira Mok and Sophie Kelly describes how Chelsea and East Boston have a higher burden of pollution and negative health consequences compared to more wealthy parts of Boston, which benefit from industry in these neighborhoods. Their project “What Does Chelsea Do for You?” led to an infographic and online quiz about the debt Boston residents owe to these areas.
Northeastern University green chemistry education symposium, a presentation by Olivia Sterns, Umin Jalloh, Christopher Mahir, Christina McConney, and Angelica Fiuza, describes a sustainable and environmentally responsible chemistry curriculum and plans for a related conference. You can also check out the organization Beyond Benign.
The impact of biological knowledge on pro-environmental behavior is a presentation by Kyleigh Watson, Kelly Marchese, Jasmine Ho, and Daniela Ras that explores the relationship between study participants’ knowledge of nature, urbanicity, and implicit and explicit connection to the natural world.
Podcast Episodes
The What’s New podcast, hosted by Dean of the Library Dan Cohen, is one of the most popular collections in the DRS. It consists of wide-ranging conversations with faculty members across the university.
How We Respond to Disaster (season 1, episode 1) — Professor of Political Science and Founding Director of the Global Resilience Institute Stephen Flynn talks about how communities come together in the wake of disasters, including increasingly common extreme weather events.
Ethics and the Environment (season 3, episode 13) — Director of the Ethics Institute Ron Sandler discusses climate change and how we can ethically respond to the moment.
The DRS team also works with professors to host student coursework in the repository.
The course Gender, Race, and Medicine (WMNS 1225), taught by Moya Bailey, included the creation of a podcast series. In the episode How Boston Institutions Impact the Health of Neighborhoods: Tufts Medical Center and Northeastern University, Celene Chen and Paulina Demirev discuss a variety of issues surrounding gentrification, including the fight against a parking garage in Chinatown that would likely have led to increased pollution. Northeastern University Archives and Special Collections holds the records of the Chinese Progressive Association, one of the groups that protested against the garage.
These selections demonstrate how the DRS documents both the climate crisis and the innovation solutions emerging from Northeastern’s academic community.